
Algorithm Workflow
Our multi-stage deep learning pipeline designed for accurate and reliable toxicity prediction.
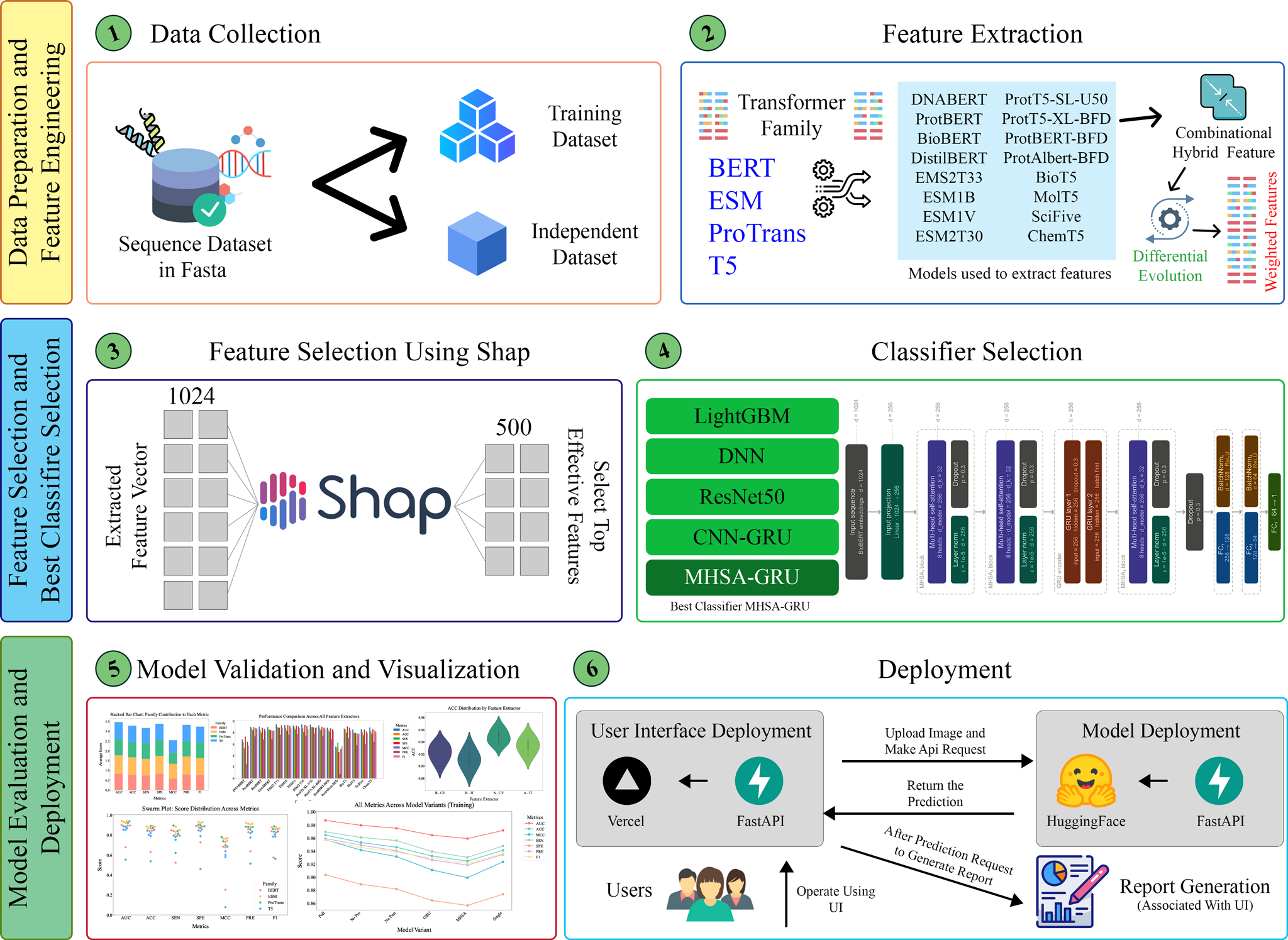
Methodology & Approach
Detailed breakdown of our multi-stage deep learning approach
Stage 1: Transformer-Based Feature Extraction
ProtBERT embedding extraction
ESM2-T33 embedding extraction
ProtT5-XL-U50 embedding extraction
BioT5 embedding extraction
Stage 2: Feature Fusion
Differential Evolution (DE) optimization
Search for optimal weighted fusion of all transformer families
Produce unified multi-model feature vector
Stage 3: SHAP Feature Selection
Compute SHAP values for fused features
Select top 500 most informative features
Stage 4: Classification
MHSA-GRU (Multi-Head Self Attention GRU)
Final toxicity prediction
Confidence estimation
Key Innovations
Novel contributions and technological advances in our approach
Fusion of four transformer-model families
Differential Evolution for optimal feature integration
SHAP-based feature selection
MHSA-GRU classifier for sequential modeling
Highly interpretable toxicity predictions
Technical Architecture
Deep learning pipeline components and model architecture
Feature Extraction
ProtBERT
Bidirectional transformer pretrained on protein sequences
ESM2-T33
33-layer evolutionary-scale model for deep protein understanding
ProtT5-XL-U50
Large T5-based transformer optimized for protein embeddings
BioT5
Biomedical T5 model adapted for representation
Feature Fusion
Differential Evolution
Optimizes weighted combination of transformer features
Feature Selection
SHAP
Select top 500 most important fused features
Classification
MHSA-GRU
Multi-Head Self Attention GRU classifier
Confidence Estimation
Final toxicity probability score
Model Performance Metrics
Experience Our Algorithm in Action
Experience our multi-stage deep learning pipeline by testing your own sequences or exploring our sample dataset for toxicity prediction.